如何阅读Android系统源码
单例模式
不管以哪种形式实现单例模式,它们的核心原理都是将构造函数私有化,并且通过静态方法获取唯一的单个实例,在这个获取的过程中必须保证线程安全,防止反序列化导致重新生成实例对象等问题。
RxJava
使用Scheduler可以管理订阅者和被订阅者的处理线程,并且通过Scheduler.Worker直接实现线程调度和延迟周期逻辑。
Okhttp
Volley
Retrofit
里面使用到的注解是编译时注解还是运行时注解 ?
Dagger
EventBus
ButterKnife
编译期注解的依赖--annotationProcessor
用过butterknife或者Dagger的同学可能对这种annotationProcessor引入方式有所印象,这种方式是只在编译的时候执行依赖的库,但是库最终不打包到apk中。结合编译期注解的作用,他是用来生成代码的,本身在运行时是不需要的。
Glide
Glide缓存与解码复用
Glide有4级缓存,按优先级高低分类
活动资源(Resource Type)
活动资源中是一个”引用计数”的图片资源的弱引用集合。同一张图片可能在多个地方被同时使用,每一次使用都会将引用计数+1,而当引用计数为0时候,则表示这个图片没有被使用也就是没有强引用了。这样则会将图片从活动资源中移除,并加入内存缓存。
内存缓存
内存缓存默认使用LRU(缓存淘汰算法/最近最少使用算法),当资源从活动资源移除的时候,会加入此缓存。使用图片的时候会主动从此缓存移除,加入活动资源。
磁盘缓存(磁盘缓存同样使用LRU算法)
1,资源类型
Resource 缓存的是经过解码后的图片,如果再使用就不需要再去进行解码配置,再次使用此图片的时候就可以直接从 Resource 获得。不需要去计算inSampleSize(缩放因子)。
2,原始数据
缓存的则是图像原始数据。
在调用into之后,Glide会首先从Active Resources查找当前是否有对应的活跃图片,没有则查找内存缓存,没有则查找资源类型,没有则查找数据来源。
网络/文件 获取图片在解析图片的时候会需要可以获得BitmapPool(复用池),达到复用的效果。Bitmap复用,解决的是减少频繁申请内存带来的性能(抖动、碎片)问题。BitmapPool是Glide中的Bitmap复用池,同样适用LRU来进行管理。当一个Bitmap从内存缓存 被动 的被移除(内存紧张、达到maxSize)的时候并不会被recycle。而是加入这个BitmapPool,只有从这个BitmapPool 被动被移除的时候,Bitmap的内存才会真正被recycle释放。

Glide加载图片是这么做的?可以结合上面的知识点重新审视这个问题。
EventBus
SparseBooleanArray
LongSparseArray
SparseArray
private LongSparseArray
void clearTransientStateViews() {
final SparseArray<View> viewsByPos = mTransientStateViews;
if (viewsByPos != null) {
final int N = viewsByPos.size();
for (int i = 0; i < N; i++) {
removeDetachedView(viewsByPos.valueAt(i), false);
}
viewsByPos.clear();
}
final LongSparseArray<View> viewsById = mTransientStateViewsById;
if (viewsById != null) {
final int N = viewsById.size();
for (int i = 0; i < N; i++) {
removeDetachedView(viewsById.valueAt(i), false);
}
viewsById.clear();
}
}
//缓存废弃的View
ArrayList<View>[] scrapViews = new ArrayList[viewTypeCount];
for (int i = 0; i < viewTypeCount; i++) {
scrapViews[i] = new ArrayList<View>();
}
View getActiveView(int position) {
int index = position - mFirstActivePosition;
final View[] activeViews = mActiveViews;
if (index >=0 && index < activeViews.length) {
final View match = activeViews[index];
activeViews[index] = null;
return match;
}
return null;
}
ListView源码分析
Adapter又是一个接口(interface),它可以去实现各种各样的子类,每个子类都能通过自己的逻辑来去完成特定的功能,以及与特定数据源的适配操作,比如说ArrayAdapter可以用于数组和List类型的数据源适配,SimpleCursorAdapter可以用于游标类型的数据源适配,这样就非常巧妙地把数据源适配困难的问题解决掉了,并且还拥有相当不错的扩展性。
RecycleBin机制:
这个机制也是ListView能够实现成百上千条数据都不会OOM最重要的一个原因。RecycleBin的代码并不多,只有300行左右,它是写在AbsListView中的一个内部类,所以所有继承自AbsListView的子类,也就是ListView和GridView,都可以使用这个机制。
View的执行流程无非就分为三步,onMeasure()用于测量View的大小,onLayout()用于确定View的布局,onDraw()用于将View绘制到界面上。而在ListView当中,onMeasure()并没有什么特殊的地方,因为它终归是一个View,占用的空间最多并且通常也就是整个屏幕。onDraw()在ListView当中也没有什么意义,因为ListView本身并不负责绘制,而是由ListView当中的子元素来进行绘制的。那么ListView大部分的神奇功能其实都是在onLayout()方法中进行的了。
ListView一共有2次Layout
1, 第一次layout过程当中,所有的子View都是调用LayoutInflater的inflate()方法加载出来的,这样就会相对比较耗时。我们的Adapter中有一千条数据,ListView也只会加载第一屏的数据,剩下的数据反正目前在屏幕上也看不到,所以不会去做多余的加载工作,这样就可以保证ListView中的内容能够迅速展示到屏幕上。到此为止,第一次Layout过程结束。
2,RecycleBin的fillActiveViews()方法(屏幕上可见的所有的子View都会被缓存到RecycleBin的mActiveViews数组当中) -》 detachAllViewsFromParent() (将所有ListView当中的子View全部清除掉,从而保证第二次Layout过程不会产生一份重复的数据) -》 待会儿将会直接使用fillActiveViews方法缓存好的View来进行加载,而并不会重新执行一遍inflate过程,因此效率方面并不会有什么明显的影响。 而如果是想要将一个之前detach的View重新attach到ViewGroup上,就应该调用attachViewToParent()方法。那么由于前面在layoutChildren()方法当中调用了detachAllViewsFromParent()方法,这样ListView中所有的子View都是处于detach状态的,所以这里attachViewToParent()方法是正确的选择。
滑动加载更多数据
在onTouchEvent()方法当中进行的,我们就来看一下AbsListView中的这个方法,我们目前所关心的就只有手指在屏幕上滑动这一个事件而已,对应的是ACTION_MOVE这个动作。
当ListView向下滑动的时候,就会进入一个for循环当中,从上往下依次获取子View,第47行当中,如果该子View的bottom值已经小于top值了,就说明这个子View已经移出屏幕了,所以会调用RecycleBin的addScrapView()方法将这个View加入到废弃缓存当中,并将count计数器加1,计数器用于记录有多少个子View被移出了屏幕。那么如果是ListView向上滑动的话,其实过程是基本相同的,只不过变成了从下往上依次获取子View,然后判断该子View的top值是不是大于bottom值了,如果大于的话说明子View已经移出了屏幕,同样把它加入到废弃缓存中,并将计数器加1。
滑动边界值判断:
接下来在第76行,会根据当前计数器的值来进行一个detach操作,它的作用就是把所有移出屏幕的子View全部detach掉,在ListView的概念当中,所有看不到的View就没有必要为它进行保存,因为屏幕外还有成百上千条数据等着显示呢,一个好的回收策略才能保证ListView的高性能和高效率。紧接着在第78行调用了offsetChildrenTopAndBottom()方法,并将incrementalDeltaY作为参数传入,这个方法的作用是让ListView中所有的子View都按照传入的参数值进行相应的偏移,这样就实现了随着手指的拖动,ListView的内容也会随着滚动的效果。
然后在第84行会进行判断,如果ListView中最后一个View的底部已经移入了屏幕,或者ListView中第一个View的顶部移入了屏幕,就会调用fillGap()方法,那么因此我们就可以猜出fillGap()方法是用来加载屏幕外数据的,
刚才在trackMotionScroll()方法中我们就已经看到了,一旦有任何子View被移出了屏幕,就会将它加入到废弃缓存中,而从obtainView()方法中的逻辑来看,一旦有新的数据需要显示到屏幕上,就会尝试从废弃缓存中获取View。所以它们之间就形成了一个生产者和消费者的模式,那么ListView神奇的地方也就在这里体现出来了,不管你有任意多条数据需要显示,ListView中的子View其实来来回回就那么几个,移出屏幕的子View会很快被移入屏幕的数据重新利用起来,因而不管我们加载多少数据都不会出现OOM的情况,甚至内存都不会有所增加。
@Override
public View getView(int position, View convertView, ViewGroup parent) {
Fruit fruit = getItem(position);
View view;
if (convertView == null) {
view = LayoutInflater.from(getContext()).inflate(resourceId, null);
} else {
view = convertView;
}
ImageView fruitImage = (ImageView) view.findViewById(R.id.fruit_image);
TextView fruitName = (TextView) view.findViewById(R.id.fruit_name);
fruitImage.setImageResource(fruit.getImageId());
fruitName.setText(fruit.getName());
return view;
}
第二个参数就是我们最熟悉的convertView呀,难怪平时我们在写getView()方法是要判断一下convertView是不是等于null,如果等于null才调用inflate()方法来加载布局,不等于null就可以直接利用convertView,因为convertView就是我们之间利用过的View,只不过被移出屏幕后进入到了废弃缓存中,现在又重新拿出来使用而已。然后我们只需要把convertView中的数据更新成当前位置上应该显示的数据,那么看起来就好像是全新加载出来的一个布局一样,这背后的道理你是不是已经完全搞明白了? 之后的代码又都是我们熟悉的流程了,从缓存中拿到子View之后再调用setupChild()方法将它重新attach到ListView当中,因为缓存中的View也是之前从ListView中detach掉的,这部分代码就不再重复进行分析了。
RecyclerView的缓存
Recycler是用于管理废弃的item或者从RecyclerView中移除的View便于复用,废弃的View是指仍然依附在RecyclerView中,但是已经被标记为移除的或者可以复用的。
跟ListView的RecycleBin一样,Recycler也是RecyclerView设计的一个专门用于回收ViewHolder的类,其实RecyclerView的缓存机制是在ListView的缓存机制的基础上进一步的完善,所以在Recycler中能看到很多跟RecycleBin一样的设计思想,在缓存这个层面上,RecyclerView实际上并没有做出太大的创新,最大的创新来源于给每一个ViewHolder增加了一个UpdateOp,通过这个标志可以进行定向刷新指定的Item,并且通过Payload参数可以对Item进行局部刷新,我觉得这个是RecyclerView最厉害的地方,大大提高了刷新时候的性能,如果数据源需要经常变动,那么RecyclerView是你最好的选择,没有之一。
RecyclerView实际上并没有做出太大的创新,最大的创新来源于给每一个ViewHolder增加了一个UpdateOp,通过这个标志可以进行定向刷新指定的Item,并且通过Payload参数可以对Item进行局部刷新,我觉得这个是RecyclerView最厉害的地方,大大提高了刷新时候的性能,如果数据源需要经常变动,那么RecyclerView是你最好的选择。
mRecyclerPool是RecycledViewPool的集合,用来缓存RecyclerView的集合,可以实现RecyclerView的复用。
对比RecyclerView与ListView的缓存机制
https://mp.weixin.qq.com/s/LAm4m9klItuQpr4Sd2_mvQ
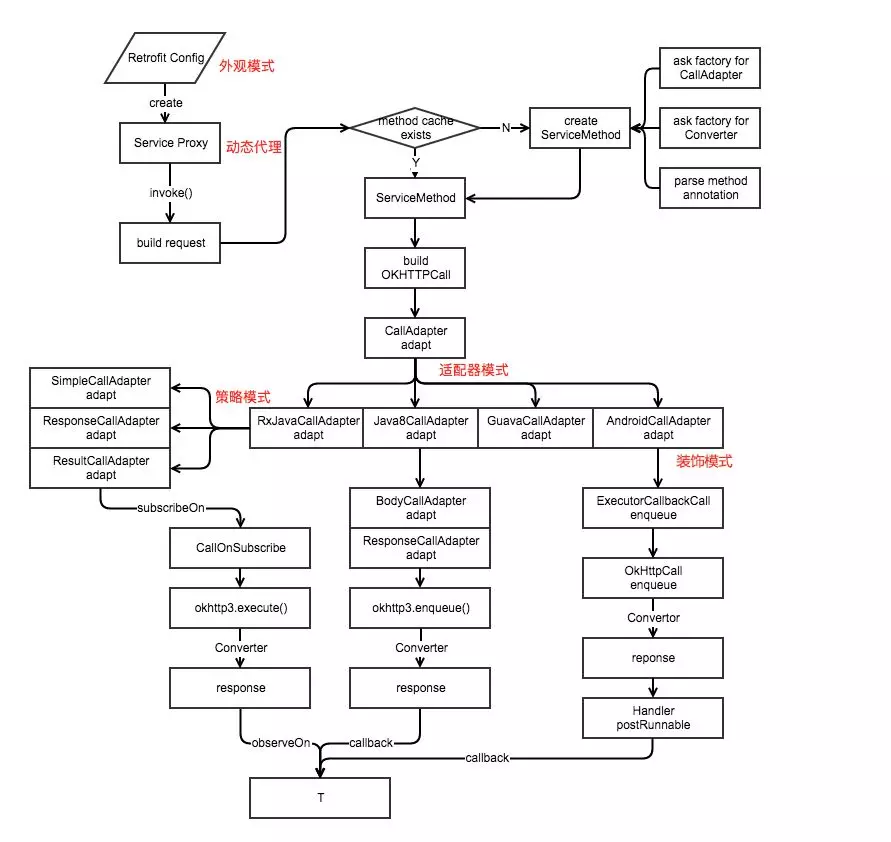
Retrofit的源码中,通过组合,将各种设计模式应用在一起,构成了整个框架,保证了我们常说的高内聚,低耦合,堪称设计模式学习案例的典范。
实际上,并没有BlogService这个对象的创建,service只不过是在jvm运行时动态生成的一个proxy对象,这个proxy对象的意义是,为其他对象提供一种代理以控制对这个对象的访问。通过BlogService进行网络请求,Retrofit就会通过动态代理实现一个proxy对象代理BlogService的行为,当我调用它的某个方法请求网络时,实际上是这个proxy对象通过解析你的注解和方法的参数,通过一系列的逻辑包装成一个网络请求的OkHttpCall对象,并请求网络。